Go project layout with Clean architectures and DDD
Introduction
During the last 5 years I have been working full time with Go. Some of you may already know that I’m in love with this language because of the simplicity it has but with a lot of potential to build anything. The main question I have faced since the beginning is Which layout should I use for my project? I would say still today I don’t know and as always in our industry… it depends. It depends on if you are building a library, it depends on if you are building a monolithic application (like MVC), it depends on if you are building a small service (aka microservice), etc. There is nothing written of and we don’t have a lot (luckily) frameworks that force you to do things in the framework’s way (note aside that’s one of my favorite parts especially coming from Java where Spring seems to be the standard way of doing projects in Java). For the beginners sometimes that is difficult because you don’t know how to start and need to do research and read/watch some tutorials and try to mimic those layouts without knowing if you’re doing the correct things. The good point on that is as there is no standard, “all” you do will be okay (however it’s dangerous sometimes).
First approach
When I started I tried to check a lot of repos on GitHub using the tag #Go and see how people are organizing their projects. Checking smaller ones or checking the big players in the industry like Docker, Kubernetes, AWS, … My first approach was to use the still popular double folder:
/cmd
/pkg
config files (Makefile, docker, etc.)
This was the initial approach that some Go projects were adopting where inside the pkg you define all your code and in the cmd you simply create your main.go which bootstraps your application from the pkg one. This started to be so popular because some Go examples from the Go Team were used. Some months/years later some people started to question if the pkg folder was simply that, a folder, and it was not contributing anything to the project so it should be removed. For that time I was a clear defender of the cmd, pkg layout because it was a “standard” for the industry and for me it was clear where to look at the code (pkg) and where to look at the initialization of the application (cmd). This is still true, but advocating the simplicity of Go we tend to remove the packages that are just folders and give them also a meaningful name as they are part of our code (importing them and using in types, functions, etc.).
Ahá moment
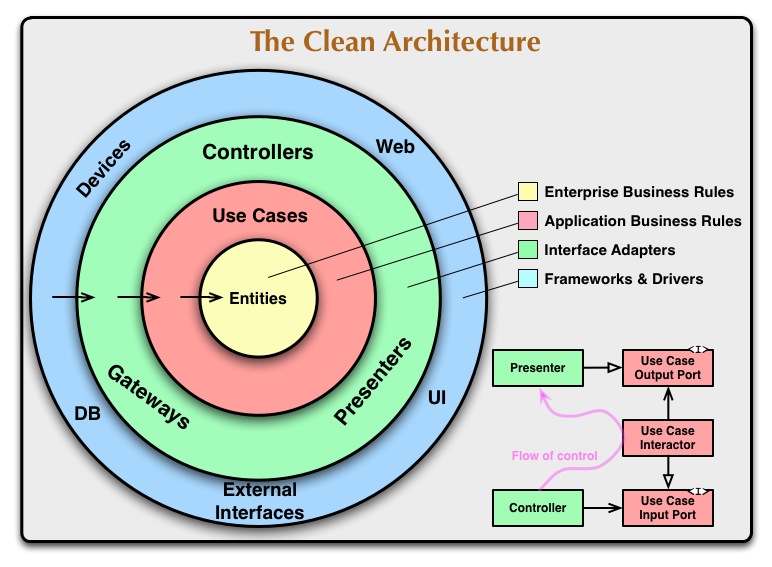
Some years ago I started reading about DDD due to the popularity it has acquired in the last years and I wanted to know what that about. I don’t want to be extenze on this post about that topic (if you would like that I write one specific for it please ping me here or through my social networks and I will be happy to do it) but basically what it aims for is to put your focus when designing in the domain instead of in the code. It helps you to better understand the problem by giving you a toolkit to work with the domain experts in your company in order to design the best possible solution for the problem you wanna solve. There are two main groups, the strategic patterns and the tactical patterns. Both are important but here as I want to talk about the project layout I will talk only about the tactical ones. When I read those I started to internalise that all the domain design that I was doing with the strategical patterns, all the questions that I was asking to the domain experts, the ubiquitous language we were defining and all the event storming sessions we were doing, all of that should be reflected in my code. How can I do that? There are a lot of possibilities but one possibility is using Clean Architectures. At that moment it was when I read Robert C. Martin’s book Clean Architecture: A Craftsman’s Guide to Software Structure and Design. Understanding what DDD aims for and the ideas conveyed in the book and after some refinement with my team colleagues we ended up creating a project layout in which we tried to gather all those concepts and the most important which we are comfortable working with. This is not to follow a trend or an imposition from any framework, so if we are not happy with it, we iterate it again and we tweak the parts we consider in order to facilitate our lives and specially our future selves when we need to do some fixes or add new features.
The layout
Taking in consideration all I mentioned before, let me present to you the project layout. As an example I will use an application that has outgoing and incoming payments. Both with their own aggregates and business rules that need to satisfy and expose endpoints via grpc in this case.
/payments-svc
|- app/
|- cmd/
|- docs/
|- grpc/
|- incoming/
|- internal/
|- logger/
|- postgres/
|- slack/
|- k8s/
|- outgoing/
docker-compose.test.yml
go.mod
go.sum
Makefile
README.md
I will try to be brief and explain a bit what parts each folder contains and why we adopted that layout.
As I said this service is responsible for payments so we want to have the domain first exposed so we display incoming and outgoing as the main parts of the application. I will go back after a few lines, don’t worry.
The app is where we have the main.go to bootstrap all the applications (basically where we import the incoming and outgoing packages and some from the internal if needed).
The cmd is where we define the command line tools we need for the service. In this case we have a cli that interacts with our service.
The docs is where we put the relevant documentation for this project.
As I mentioned before the endpoints are exposed via grpc so that folder is responsible for implementing the interfaces provided by the protobuffer compilation.
The internal is where we have the implementation of the interfaces we use in the project but are not part of the domain; basically the infrastructure things like the database, queues, external services (Slack), the logger…
The k8s one is referred to the Kubernetes config files for the deployment.
As mentioned before the incoming and outgoing are our domain packages so that is where all the magic happens. I will describe a bit of one of them because the other is similar but with the particularities of that domain.
/outgoing
app_service.go
app_service_test.go
display_payments.go
display_payments_test.go
execute_payments.go
execute_payments_test.go
flow_service.go
flow_service_test.go
instruction_repository.go
instruction_repository_test.go
instruction.go
instruction_test.go
I’ve picked up the outgoing for the explanation. First of all we have the app_service. This is where we define the type Application Service of our package so what it means is that it will have all the dependencies for the package and one method for each Use Case. Note: the dependencies are interfaces. The app_service_test is basically where we mock all the interfaces required for the app_service so we can reuse them in all the *_test.go files.
The display_payments and execute_payments are use cases for this domain. The tests are simply testing the different scenarios for each use case.
The flow_service is a domain service that helps us to execute the payments depending on the flow defined for each payment type. The test is basically testing the domain service.
The instruction_repository is where we define all the methods against our repository, in this case our database in PostgreSQL. The test is checking against a testing database if all the queries are okay.
Last but not least, actually the most important is the aggregate instruction. Inside that file is where we put everything important for this package. The aggregate is in charge of enforcing the business rules so that all the validations, checks, calculations, conversions, etc. needs to be here. (It’s true that depending on the conversion or manipulation of the data or complex operations, it’s better to have factories or other helpers, but I don’t want to overcomplicate this example).
Application flow
To finalize this long post let me describe how the flow of our app works:
appis the responsible of starting up the servicegrpcwill be the one receiving the request and answers the results- once the request is mapped into our internal types by
grpcit will call theapp_service - inside the
app_servicethe correspondinguse casewill be called - depending on the
use casesomedomain serviceshould be called, somerepositorywill be called, or both, or more than 2… It depends!
Conclusion
I hope everything that I have tried to explain in this post has been clear, which was a lot, and please if there is any part that has not been completely clear or there are parts that I have not covered that you would like me to do, leave me a comment right here or through my social networks that you have on my profile and I will be happy to respond.