Estructura de proyecto para Go con Arquitecturas Limpias y DDD
Introducción
Durante los últimos 5 años he trabajado a tiempo completo con Go. Algunos de ustedes ya sabrán que estoy enamorado de este lenguaje por la simplicidad que tiene pero con mucho potencial para construir cualquier cosa. La principal pregunta a la que me he enfrentado desde el principio es ¿Qué estructura debo usar para mi proyecto? Yo diría que todavía hoy no lo sé y como siempre en nuestra industria… depende. Depende de si está creando una libreria, depende de si está creando una aplicación monolítica (como MVC), depende de si está creando un pequeño servicio (también conocido como microservicio), etc. No hay nada escrito y no hay muchos frameworks (afortunadamente) que te obligan a hacer las cosas a la manera del mismo (tenga en cuenta que esa es una de mis partes favoritas, especialmente viniendo de Java, donde Spring parece ser la forma estándar de hacer proyectos en Java). Para los principiantes, a veces eso es lo difícil porque no sabes cómo empezar y necesitas investigar y leer/ver algunos tutoriales y tratar de imitar esos diseños sin saber si estás haciendo las cosas correctamente. Lo bueno de esto es que, como no existe un estándar, “todo” lo que hagas estará bien (aunque a veces es peligroso).
Primer enfoque
Cuando comencé, busqué muchos repositorios en GitHub usando la etiqueta #Go y ver cómo las personas estaban organizando sus proyectos. Comprobando desde los más pequeños hasta los más grandes de la industria como Docker, Kubernetes, AWS, … Mi primer enfoque fue usar la todavía popular doble carpeta:
/cmd
/pkg
archivos de configuración (Makefile, docker, etc.)
Este fue el enfoque inicial que estaban adoptando algunos proyectos de Go, donde dentro del pkg usted define todo su código y en el cmd simplemente crea su main.go el cuál arranca su aplicación desde el pkg. Esto comenzó a ser tan popular porque se utilizaron algunos ejemplos de Go del equipo de Go. Algunos meses / años después, algunas personas comenzaron a preguntarse si la carpeta pkg era simplemente eso, una carpeta, y no contribuía en nada al proyecto, por lo que debería eliminarse. En ese momento yo era un claro defensor del diseño cmd, pkg porque era un “estándar” para la industria y para mí estaba claro dónde mirar el código (pkg) y dónde mirar la inicialización de la aplicación (cmd). Esto sigue siendo cierto, pero defendiendo la simplicidad de Go, tendemos a eliminar los paquetes que son solo carpetas y darles también un nombre significativo, ya que son parte de nuestro código (importándolos y usándolos en tipos, funciones, etc.).
Momento Ahá
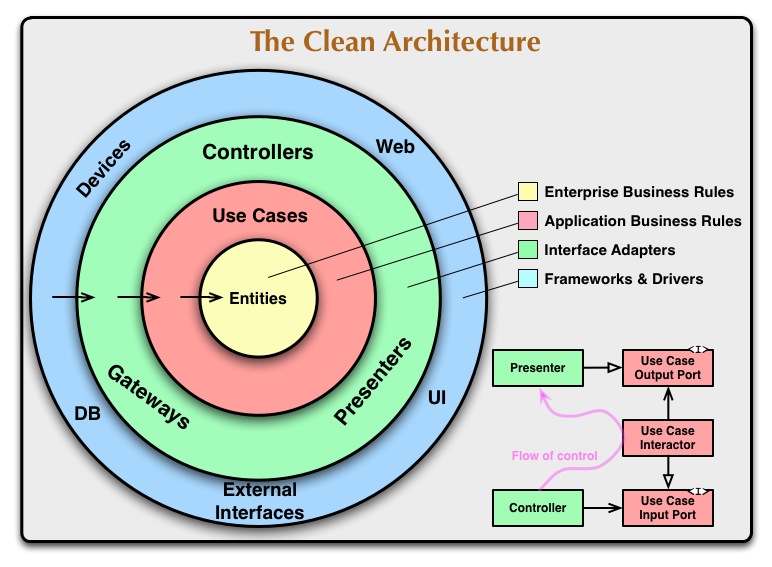
Hace unos años comencé a leer sobre DDD debido a la popularidad que ha adquirido en los últimos años y quería saber de qué se trata. No quiero extenderme en este post sobre ese tema (si desea que escriba uno específico para él, envíeme un mensaje aquí o a través de mis redes sociales y estaré feliz de hacerlo) pero básicamente a lo que apunta es a concentrarse al diseñar en el dominio en lugar de en el código. Le ayuda a comprender mejor el problema al brindarle un conjunto de herramientas para trabajar con los expertos en el dominio de su empresa a fin de diseñar la mejor solución posible para el problema que desea resolver. Hay dos grupos principales, los patrones estratégicos y los patrones tácticos. Ambos son importantes, pero aquí, como quiero hablar sobre el diseño del proyecto, solo hablaré de los tácticos. Cuando leí esos, comencé a internalizar que todo el diseño de dominio que estaba haciendo con los patrones estratégicos, todas las preguntas que le hacía a los expertos en el dominio, el lenguaje ubicuo que estábamos definiendo y todas las sesiones de tormenta de eventos que estábamos haciendo, todo eso debería reflejarse en mi código. ¿Cómo puedo hacer eso? Hay muchas posibilidades, pero una posibilidad es usar Clean Architectures. En ese momento fue cuando leí el libro de Robert C. Martin Clean Architecture: A Craftsman’s Guide to Software Structure and Design. Entendiendo los objetivos de DDD y las ideas transmitidas en el libro y después de un refinamiento con los compañeros de mi equipo, terminamos creando un diseño de proyecto en el que intentamos reunir todos esos conceptos y los más importantes con los que nos sentimos cómodos trabajando. Esto no es para seguir una tendencia o una imposición de ningún marco, por lo que si no estamos contentos con él, lo repetimos nuevamente y retocamos las partes que consideramos para facilitar nuestra vida y especialmente nuestro yo futuro cuando lo necesitemos. algunas correcciones o agregar nuevas funciones.
El diseño
Teniendo en cuenta todo lo que mencioné antes, permítanme presentarles el diseño del proyecto. Como ejemplo, usaré una aplicación que tiene salientes y pagos recibidos. Ambos con sus propios agregados y reglas comerciales que deben satisfacer y exponer los endpoints a través de grpc en este caso.
/payments-svc
| - app /
| - cmd /
| - docs /
| - grpc /
| - incoming /
| - internal /
|- logger/
|- postgres/
|- slack/
| - k8s /
| - outgoing /
docker-compose.test.yml
go.mod
go.sum
Makefile
README.md
Intentaré ser breve y explicar un poco qué partes contiene cada carpeta y por qué adoptamos ese diseño.
Como dije, este servicio es responsable de los pagos, por lo que queremos que el dominio se exponga primero, por lo que mostramos incoming y outgoing como las partes principales de la aplicación. Entraré en detalle unas líneas después, no se preocupe.
En app es donde tenemos el main.go para arrancar todas las aplicaciones (básicamente donde importamos los paquetes incoming y outgoing y algunos internal si es necesario).
En cmd es donde definimos las herramientas de línea de comando que necesitamos para el servicio. En este caso tenemos un cli que interactúa con nuestro servicio.
En docs es donde colocamos la documentación relevante para este proyecto.
Como mencioné antes, los endpoints se exponen a través de grpc, por lo que la carpeta es responsable de implementar las interfaces proporcionadas por la compilación de nuestro protobuffer.
En internal es donde tenemos la implementación de las interfaces que usamos en el proyecto pero que no son parte del dominio; básicamente las cosas de la infraestructura como la base de datos, las colas, los servicios externos (Slack), el logger…
En k8s se refiere a los archivos de configuración de Kubernetes para la implementación.
Como se mencionó antes, incoming y outgoing son nuestros paquetes de dominio, así que ahí es donde ocurre toda la magia. Describiré un poco uno de ellos porque el otro es similar pero con las particularidades de su dominio.
/outgoing
app_service.go
app_service_test.go
display_payments.go
display_payments_test.go
execute_payments.go
execute_payments_test.go
flow_service.go
flow_service_test.go
instruction_repository.go
instruction_repository_test.go
instruction.go
instruction_test.go
Recogí el “saliente” para la explicación. En primer lugar tenemos el app_service. Aquí es donde definimos el tipo Application Service de nuestro paquete, entonces lo que significa es que tendrá todas las dependencias para el paquete y un método para cada Caso de Uso. Nota: las dependencias son interfaces. El app_service_test es básicamente donde mockeamos todas las interfaces necesarias para el app_service para poder reutilizarlas en todos los archivos *_test.go.
Los ficheros display_payments y execute_payments son casos de uso para este dominio. Las test simplemente prueban los diferentes escenarios para cada caso de uso.
El flow_service es un servicio de dominio que nos ayuda a ejecutar los pagos en función del flujo definido para cada tipo de pago. Básicamente, el test consiste en probar el servicio de dominio.
El instruction_repository es donde definimos todos los métodos contra nuestro repositorio, en este caso nuestra base de datos en PostgreSQL. En el test se compara con una base de datos de prueba si todas las consultas están bien.
Por último, pero no menos importante, en realidad lo más importante el agregado instruction. Dentro de ese archivo es donde ponemos todo lo importante para este paquete. El agregado está a cargo de hacer cumplir las reglas de negocio por lo que todas las validaciones, verificaciones, cálculos, conversiones, etc. deben estar aquí. (Es cierto que dependiendo de la conversión o manipulaciones de datos o otras operaciones más complejas, es mejor tener factorías u otros helpers, pero no quiero complicar demasiado este ejemplo).
Flujo de la aplicación
Para finalizar este largo post, permítanme describir cómo funciona el flujo de nuestra aplicación:
appes la responsable de poner en marcha el serviciogrpcserá el que reciba la solicitud y responda los resultados- una vez que
grpcasigna la solicitud a nuestros tipos internos, llamará aapp_service - dentro de
app_servicese llamará alcaso de usocorrespondiente - dependiendo del
caso de usose debe llamar algúnservicio de dominio, se llamará algúnrepositorio, o ambos, o más de 2 … ¡Depende!
Conclusión
Espero que todo lo que he intentado explicar en este post haya sido claro, que fue mucho, y por favor si hay alguna parte que no ha sido del todo clara o hay partes que no he cubierto que te gustaría que hiciera, déjame un comentario aquí mismo oa través de mis redes sociales que tienes en mi perfil y estaré encantado de responderte.